Arabic Sentiment Analysis Using Mixup Data Augmentation Mixup
2024-06-15 | volume 2 Special Issue - HiTech Conference - Volume 2 | Research Articles | Alia Hamwi | Maisaa Aboukassem | Nada GhneimAbstract
Mixup, as a technique for augmenting data within the feature space, operates by applying linear interpolation to input instances and their associated modeling targets derived from randomly selected samples. The efficacy of this method in substantially enhancing the predictive accuracy of cutting-edge networks has been established across both image and text classification tasks. Despite its demonstrated success in various contexts, its application within the context of the Arabic language remains an unexplored area of research. This study employed three strategies to adapt Mixup for application in Arabic sentiment analysis. Experimental evaluations were conducted to assess the effectiveness of these strategies, utilizing a range of benchmark datasets. Our studies demonstrate that these interpolation strategies effectively function as domain-independent methods for augmenting data, in the context of text classification. Furthermore, these strategies have the potential to lead to enhancements in performance for both convolutional neural network (CNN) and long short-term memory (LSTM) models.
Keywords : Text Classification, Sentiment Analysis, Data Augmentation, Mixup Augmentation.
INTRODUCTION
In recent years, deep learning models have exhibited remarkable performance in numerous Natural Language Processing (NLP) tasks, such as parsing [1], text classification [2], [3] and machine translation [4]. These models are typically characterized by their substantial parameter count, often reaching millions, necessitating extensive data for training to prevent overfitting and enhance generalization capabilities. However, collecting a sizable annotated dataset proves to be a laborious and costly endeavour. To mitigate the data-hungry nature of deep learning models, an approach known as automatic data augmentation has emerged. This technique involves generating synthetic data samples to augment the training dataset, effectively serving as regularization for the learning models. Data augmentation has been actively and successfully employed in computer vision [5], [6], [7] and speech recognition tasks [8], [9]. In these domains, methods frequently rely on human knowledge to apply label-invariant data transformations, such as image scaling, flipping, and rotation. However, natural language processing presents a different challenge, as there are no straightforward rules for label-invariant transformations in textual data. Even slight changes in a word within a sentence can drastically alter its meaning. Consequently, popular data augmentation techniques in NLP focus on transforming text through word replacements, either using synonyms from manually curated ontologies, such as WordNet [10] or leveraging word similarity measures [11], [12]. Nonetheless, this synonym-based approach can only be applied to a limited portion of the vocabulary since finding words with precisely or nearly identical meanings is rare. Furthermore, certain NLP data augmentation methods are specifically designed for particular domains, rendering them less adaptable to other domains [13]. As a result, developing more versatile and effective data augmentation techniques remains a significant research challenge in the field of NLP. In recent researches, a straightforward yet highly impactful data augmentation technique called Mixup [7] has been introduced, demonstrating remarkable effectiveness in improving the accuracy of image classification models. This method operates by linearly interpolating the pixels of randomly paired images along with their corresponding training targets, thereby generating synthetic examples for the training process. The application of Mixup as a training strategy has proven to be highly effective in regularizing image classification networks, leading to notable performance improvements. Mixup methodologies can be classified into input-level Mixup [14], [15], [16] and hidden-level Mixup [17] depending on where the mix operation occurs. In the context of natural language processing (NLP), applying Mixup poses greater challenges compared to computer vision due to the discrete nature of text data and the variability in sequence lengths. As a result, prior efforts in Mixup for textual data [18], [19] have put forth two strategies for its application in text classification: one involves performing interpolation on word embedding, while the other applies it to sentence embedding. This incentive drives us to explore Mixup text techniques for low-resource languages, specifically concentrating on Arabic sentiment classification. Our study involves a comparative analysis of basic LSTM classification models, both with and without the incorporation of Mixup techniques. Furthermore, we conduct experiments on diverse datasets, spanning sample sizes varying from hundreds to thousands per class. Additionally, we perform an ablation study to investigate the effects of different Mixup parameter values. To the best of our knowledge, this represents the pioneering research utilizing Mixup in the context of Arabic text classification.
MATERIALS AND METHODS
Mixup Concept
Define abbreviations and acronyms the first time they are used in the text, even after they have been defined in the abstract. Abbreviations such as IEEE, SI, MKS, CGS, sc, dc, and rms do not have to be defined. Do not use abbreviations in the title or heads unless they are unavoidable. The concept of Mixup involves creating a synthetic sample through linear interpolation of a pair of training samples and their corresponding model targets. To elaborate, let us consider a pair of samples denoted as (xi, yi) and (xj, yj), where x represents the input data, and y is the one-hot encoding representation of the respective class label for each sample. The process of generating the synthetic sample is as follows: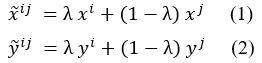 where λ could be either fixed value in [0; 1] or it is sampled from Beta distribution with a hyper-parameter Beta (α; α). The synthetic data generated using this approach are subsequently introduced into the model during training, aiming to minimize the loss function, such as the cross-entropy function typically employed in supervised classification tasks. To achieve computational efficiency, the mixing process involves randomly selecting one sample and pairing it with another sample drawn from the same mini-batch.
where λ could be either fixed value in [0; 1] or it is sampled from Beta distribution with a hyper-parameter Beta (α; α). The synthetic data generated using this approach are subsequently introduced into the model during training, aiming to minimize the loss function, such as the cross-entropy function typically employed in supervised classification tasks. To achieve computational efficiency, the mixing process involves randomly selecting one sample and pairing it with another sample drawn from the same mini-batch.
Mixup for text classification
In contrast to images that comprise pixels, sentences are composed of sequences of words. Consequently, constructing a meaningful sentence representation involves aggregating information from this word sequence. In typical CNN or LSTM models, a sentence is initially represented as a sequence of word embedding and then processed through a sentence encoder. Commonly used sentence encoders include CNN and LSTM architectures. The resulting sentence embedding, generated by either CNN or LSTM, is subsequently passed through a softmax layer to generate the predictive distribution encompassing the possible target classes for making predictions. In [18], Guo introduced two variations of Mixup tailored for sentence classification. The first variant, referred to as wordMixup, employs sample interpolation within the word embedding space. The second variant, known as senMixup, performs interpolation on the final hidden layer of the network just before it is fed into the standard softmax layer to generate the predictive distribution across classes. Specifically, in the wordMixup technique, all sentences are first zero-padded to a uniform length. Subsequently, interpolation is performed for each dimension of every word within a sentence. Let us consider a given text, such as a sentence consisting of N words, which can be represented as a matrix B in an N × d form. Here, each row t of the matrix corresponds to an individual word, denoted as Bt, and is represented by a d-dimensional vector obtained either from a pre-trained word embedding table or randomly generated. To formalize the process, let (Bi, yi) and (Bj, yj) be a pair of samples, where Bi and Bj represent the embedding vectors of the input sentence pairs, and yi and yj correspond to their respective class labels, represented in a one-hot format. For a specific word at the t-th position in the sentence, the interpolation procedure is applied. The process can be formulated as:
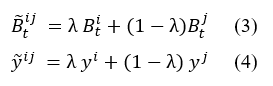
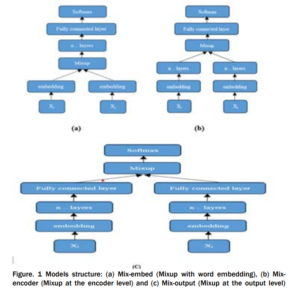
The obtained novel sample〖(B ̃〗^ij;y ̃^ij) is subsequently employed for training purposes. As for senMixup, the hidden embeddings for both sentences, having identical dimensions, are initially generated using an encoder like CNN or LSTM. Following this, the pair of sentence embeddings, f(Bi) and f(Bj), is linearly interpolated. In more detail, let f represent the sentence encoder; thus, the sentences Bi and Bj are first encoded into their corresponding sentence embedding, f(Bi) and f(Bj), respectively. In this scenario, the mixing process is applied to each kth dimension of the sentence embedding as follows.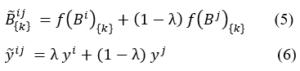 The sentMixup usually applies Mixup directly before the softmax while we experimented with an additional Mixup type that works on the hidden layers output similar to [17] applying Mixup before the final linear layer. Th proposed models’ structures are represented in Fig. 1.
The sentMixup usually applies Mixup directly before the softmax while we experimented with an additional Mixup type that works on the hidden layers output similar to [17] applying Mixup before the final linear layer. Th proposed models’ structures are represented in Fig. 1.
 Datasets
Datasets
We performed experiments using 8 Arabic sentiment classification benchmark datasets: ArSarcasm v1 [36] & v2 [37], SemEval2017 [38], ArSenTD-LEV [39], AJGT [40], ASTD-3C [41], MOV [42]. The training sets differ in size (from 12548 to 1524), and in number of labels (2 to 5). The used datasets are summarized in Table 1.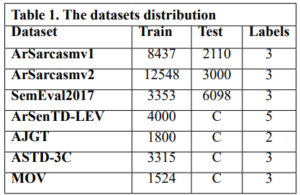 Preprocessing
Preprocessing
The effectiveness of sentiment analysis models greatly depends on the quality of data preprocessing, which is equally critical as the model’s architectural design. Preprocessing involves cleaning and preparation of the text data for the classification process. Textual data, particularly when sourced from the internet, tends to be unstructured, necessitating additional processing steps for proper classification. The noise removal step during text data preprocessing involves eliminating several elements to enhance data quality. These elements encompass punctuation marks, numbers, non-Arabic text, URL links, hashtags, emojis, extra characters, diacritics, and elongated letters. Regular expressions serve as the primary technique for noise removal, effectively filtering out unwanted text.
Experimental environment and hardware
The experiments were developed using Python 3.9.7. The experiments, including their development, implementation, execution, and analysis, were conducted on an ASUS ROG G531GT Notebook. This machine runs Windows 11 and is equipped with a 9th generation Intel Core i7 processor, 32GB of RAM, a 512GB NVMe SSD, and an NVIDIA GeForce GTX 1650 4GB graphics card. The software libraries used in this study include PyTorch, Scikit-learn, Pandas, Gensim, and NumPy.
Model
We conducted an evaluation of wordMixup and senMixup using both CNN and LSTM architectures for sentence classification. In our setup, we employed filter sizes of 3, 4, and 5, each configured with 100 feature maps, and a dropout rate of 0.5 for the baseline CNN. For the LSTM model, we utilized 3 hidden layers, each comprising 100 hidden state dimensions, with the activation function set to tanh. Additionally, the mixing policy parameter is set to the default value of one. In cases where datasets lacked a standard test set, we adopted cross-validation with a k-fold value of 5 and reported the average performance metrics. Our training process utilized the Adam optimizer [36] with mini-batches of size 32 with 30 epochs and a learning rate of 1e-3. For word embedding, we employed 100-dimensional Aravec embedding.
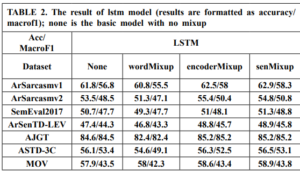
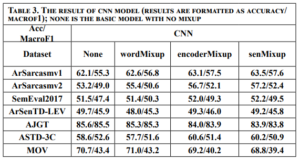
DISCUSSION
Across the datasets, it is evident that applying Mixup techniques generally leads to slight improvements in accuracy compared to the baseline None model. However, the effectiveness of Mixup varies depending on the dataset. For instance, on the AJGT dataset, all Mixup variants consistently outperform the None model, with Mix-encoder and Mix-output achieving the highest accuracy of 85.2%. On the other hand, for the SemEval2017 and ArSenTD-LEV datasets, Mixup provides only marginal gains, suggesting that the impact of Mixup might be more prominent in certain scenarios. Additionally, while Mixup seems to be beneficial in some cases, it does not necessarily lead to performance improvements across all datasets. For instance, on the MOV dataset, the Mixup variants show comparable or slightly worse results compared to the None model. Furthermore, it is worth noting that the Mix-encoder and Mix-output models tend to perform better than the Mix-embed model in most cases. This could be attributed to the advantage of applying Mixup at the higher levels of the model architecture, which allows the model to capture more abstract and meaningful patterns. Mixup augments data by interpolating sequences, which can create new variations that capture a broader range of sequential patterns. LSTMs, with their capability to understand and generalize sequences over long contexts, can leverage these variations more effectively than CNNs, which focus more on local patterns and may not fully utilize the sequential nature of the augmented data. Overall, these results demonstrate that Mixup techniques can be advantageous to sentiment analysis tasks, but their effectiveness is influenced by the dataset characteristics and the specific Mixup strategy used.
CONCLUSIONS AND RECOMMENDATIONS
Taking inspiration from the promising results of Mixup, a data augmentation technique based on sample interpolation used in image recognition and text classification, we conducted an investigation into three variations of Mixup for Arabic sentiment classification task, which is the first study on Mixup in Arabic to our knowledge. Our experiments demonstrate that the application of Mixup leads to improvements in accuracy and Macro F1 scores for both CNN and LSTM text classification models. Notably, our findings highlight the effectiveness of interpolation strategies as a domain-independent regularizer, effectively mitigating the risk of overfitting in sentence classification. These results underscore the potential of Mixup as a valuable tool in the field of NLP for enhancing model generalization and performance across various sentence classification tasks. In our future research endeavors, we have outlined our intentions to explore and examine further proposed variations of Mixup. Among these variants are AutoMix [44], a method that adaptively learns a sample mixing policy by leveraging discriminative features, SaliencyMix [32], which synthesizes sentences while maintaining the contextual structure of the original texts through span-based mixing and EMTCNN [45], an Enhanced Mixup that leverage transfer learning to address challenges in Twitter sentiment analysis. We are also interested in questions related to the visual appearance of mixed sentences and the underlying mechanisms responsible for the efficacy of interpolation in sentence classification. These inquiries will provide valuable insights into the potential applications and benefits of various Mixup techniques, contributing to the advancement of NLP tasks, particularly those focused on sentence classification.
References :
The authors declare that they have no competing interests. Author contributions: The first author conducted investigations, prepared data, executed the study, analyzed the findings, and prepared the initial draft. The second and third authors offered guidance and conducted a review of the work. Data and materials availability: All data are available in the main text or the supplementary materials.
Competing Interests :
(ISSN - Online)
2959-8591
